





Stata官方版是一款相当优秀的实用型理科统计软件,Stata官方版功能强悍,高效专业,提供了数据分析、数据管理和绘制专业图表等功能,Stata支持线性混合模型、均衡重复反复及多项式普罗比模式等数据模型,可以帮您绘制出十分精美的统计图形。
Stata功能特色
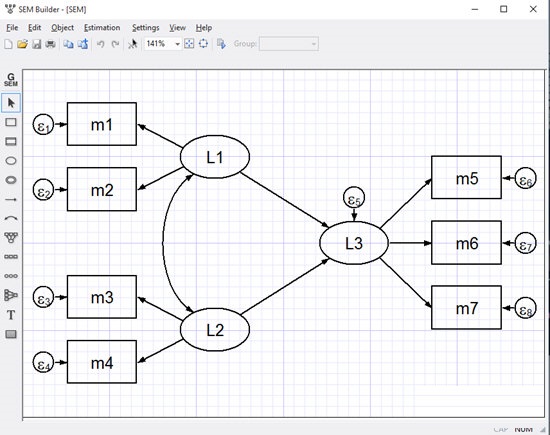
1、空间自回归模型(SAR)
Stata官方版适合空间自回归 (SAR) 模型, 也称为同步自回归模型。新的spregress,spivregress, 和spxtregress命令允许因变量的空间滞后、自变量的空间滞后和空间自回归误差。空间滞后是时间序列滞后的空间模拟。时间序列滞后近年来成为变量值。空间滞后是附近地区的值。
2、潜在类别分析(LCA)
潜在的均值未被观测。分类也就是分组。潜在类是数据中未观测到的组。你可能有关于消费者的数据,并且根据消费者对产品的潜在兴趣将他们分成三组。但是,在数据中没有指定每个消费者所属组的变量。拟合模型后,你可以
使用新的estat lcprob命令估计属于每一类的消费者比例;
使用新的estat lcprob命令估计每个类中Y1、Y2、Y3、Y4的边际均值(均值就是示例所示的概率);
使用新estat lcprob命令来评价适合度;
使用现有的predict命令获取分类成员的预测概率和观测结果变量的预测值。
3、贝叶斯前缀指令
新的bayes:前缀命令使你能够适应比以前版本更广泛的贝叶斯模型。原来也可以拟合贝叶斯线性回归, 但是现在可以通过输入文字就可以:在这个模型中, 为变量 id的每个值添加随机截距。
新的bayes:前缀命令在许多Stata评估命令之前工作,并提供超过50种可能性的模型。支持的模型包括多级、面板数据、生存和样本选择模型!
新命令支持所有Stata的贝叶斯的功能。你可以从之前的模型参数的分布中选择,也可以使用之前默认的。当闭合形式解决方案用于Gibbs方法时,可以使用默认的自适应 Metropolis–Hastings 抽样, 或Gibbs抽样, 或两种方法的组合。在bayesmh命令的基础上可以使用STATA的任何其他功能。可以更改回归系数的缺省先验分布,比如,使用prior()选项:
4、线性动态随机一般均衡(DSGE)模型
DSGEs是经济学中的一个时间序列模型。它们是传统预测模型的替代品。两者都试图解释总的经济现象, 但 DSGEs 允许对来自经济理论模型的基础上做这个。建立在经济理论基础上的方程很多。这些方程的关键特征是, 未来变量的期望值会影响今天的变量。这是区别 DSGEs 与矢量回归或状态空间模型的一个特性。另一个特点是, 从理论推导出来的参数通常可以用这个理论来解释。
在DSGE模型中有三种变量:
控制变量和方程,如p没有冲击,并且是由方程组决定的。
状态变量 (如 y) 具有隐含的冲击, 在时间段开始时是预先确定的。
冲击是驱动系统的随机错误。
在任何情况下, 以上dsge 命令可以定义一个模型并拟合。
如果我们有一个关于 beta 和kappa之间关系的理论, 比如它们是相等的, 我们可以用现有的命令test来测试它。
新的 postestimation命令estat policy和estat transition报告策略和转换矩阵。如果键入
显示将控制变量作为状态变量的线性函数。如果有五个控制变量和三个状态变量, 则每个控件将被报告为三个状态的线性函数。在上面的简单例子中, 预测 p 的线性函数将显示为现在的 y 函数。
同时,报告转换矩阵。而策略矩阵将 p 报告为函数y, 而转换矩阵则报告 y 如何通过时间演变为p。可以使用Stata的现有预测命令来生成预测。可以使用Stata现有的irf命令来绘制脉冲响应函数。
5、web动态的Markdown文档
你有没有听过Markdown?它是一种创建 html 文档的流行方式。html 文件是繁琐的。Markdown简单直观,想法很简单。可以创建一个文件, 其中包含所需的可读格式的文本, 然后通过它运行一个命令来创建一个HTML文件。
Stata现在支持Markdown, 我们已经添加了标签 (功能) 到Markdown, 允许包括输入文件中的Stata命令。你所包含的命令将被运行和显示, 或者以秘密方式运行, 以及提取输出的部分供文档使用。
6、非线性混合效应模型
非线性混合效应模型也被称为非线性多级模型和非线性层次模型。可以用两种方式来考虑这些模型。可以把它们看成包含随机效应的非线性模型。或者可以把它们看成线性混合效应模型, 其中一些或所有的固定和随机效应都是非线性的。不管哪种方式, 总的误差分布假设成Gaussian分布。
这些模型在人口药代动力学, 生物鉴定和研究生物学和农业成长过程中很流行。比如,采用非线性混合效应模型对机体的药物吸收、地震强度和植物生长进行了模拟。
新的评估命令被命名为 menl。它实现了 popular-in-practice Lindstrom–Bates 算法, 是基于对固定和随机效应的非线性均值函数进行线性化。支持最大似然和受限最大似然估计方法。
Menl易于使用。可以直接输入单个方程。大括号{ },用于将要匹配的参数括起来:
除了标准功能外, postestimation特征还包括对随机效应及其标准误差的预测,对模型中定义的感兴趣参数的预测, 作为其他模型参数和随机效应的参数、聚类相关矩阵的整体评估等。
Stata功能特点
1、Stata官方版的数据访问功能除了直接读取自身格式的数据集外,Stata支持导入/导出很多其他格式的数据集,如常用的Excel格式、XML格式、SAS XPORT格式、文本格式及ODBC接口。如果数据很少,可以直接将数据手工录入至Stata软件。
2、Stata的数据管理功能
Stata官方版为用户提供了完善的数据管理功能,举例如下:①Stata支持最多达32个字符的变量名,字符变量值支持长达20亿字节(Stata区分字符大小写);②利用数值函数或字符函数产生新变量;③自动由分组变量生成哑变量,自动将字符变量映射成数字代码;④对数据文件进行横向和纵向链接、行列变换等;⑤重复测量数据的长型格式和宽型格式相互转换;⑥数值变量和字符变量相互转换。
3、Stata的作图功能
Stata可生成可供发表的高质量的图形输出。本书主要介绍最常见的几种基本图形的制作:散点图、线图、面积图、条图、方向图等
4、Stata的统计分析功能
Stata的统计功能很强,除了传统的统计分析方法外,还收集了近年来发展起来的新方法,其分析功能紧跟国际上数理统计方法学的最新进展。Stata 13增加了许多特性,如处理效应、多水平广义线性模型、功效和样本量、广义结构方程模型、预测、效应量、删失的连续性结局、单变量时间序列模型。更为令人称赞的是,Stata在统计分析命令的设置上结构极为清晰,它将相同类型的统计模型均归在同一个命令族下,而不同命令族又可以使用相同功能的选项,这使得用户学习时极易上手。
5、Stata的矩阵运算功能
矩阵代数是多元统计分析的重要工具,Stata不但提供了多元统计分析中所需的基本矩阵运算,如矩阵的加、积、逆、Cholesky分解、Kronecker内积等,还提供了一些高级运算,如特征根、特征向量、奇异值分解等。在执行完某些统计分析命令后,还提供了一些系统矩阵,如估计系数向量、估计系数的协方差矩阵等。Stata 9.0以后版本完美地整合了执行矩阵计算的矩阵编程语言Mata,可进行强大的矩阵运算。
6、Stata的程序设计功能
Stata是一个统计分析软件,但它也具有很强的程序语言功能,给用户提供了一个广阔的开发应用的天地。和矩阵运算功能相结合,用户就能够充分发挥自己的聪明才智,熟练应用各种技巧,对Stata的功能进行扩展(详见第11章)。如Stata自身并无Meta分析命令,但是用户们开发了一整套优秀的Meta分析命令集(详见第12章),对Stata的功能进行了进一步扩展,使之成为当前最优秀的Meta分析软件之一。
Stata安装方法
1、在番茄下载站站下载Stata官方版压缩包,解压Stata官方版软件包,点击exe程序开始安装
2、点击do not accept the license agreement同意用户协议
3、选择安装模式
4、软件共有(MP/SE/IC)三个版本勾选第一个,点击next进行下一步
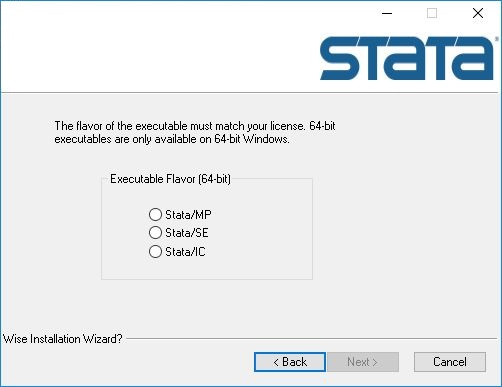
5、选择软件的安装位置,默认官方设置的地址即可C:Program Files (x86)Stata15,建议用户安装在D盘
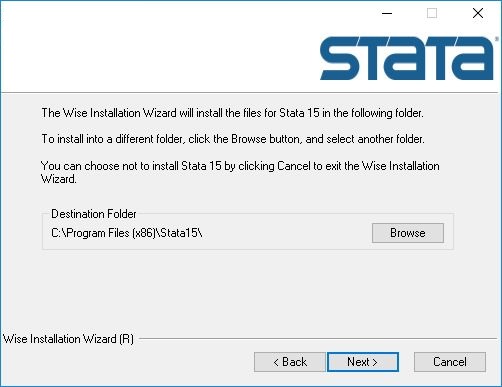
6、选择软件安装方案,点击next继续
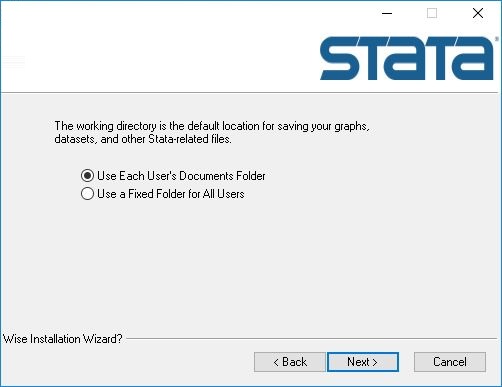
7、完成软件设置,点击install安装
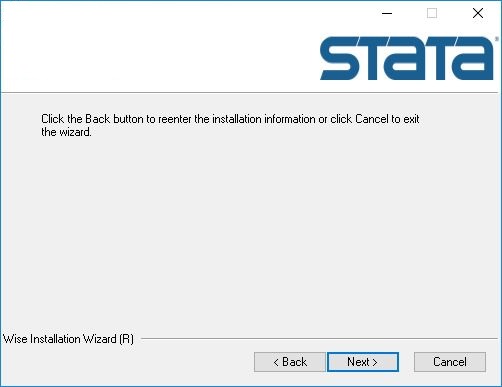
8、软件正在安装中,正在显示Stata15.1的安装进度,请稍后
9、软件已安装完成,点击finish
Stata中文设置
设置里更改Stata语言:Edit > Preferences > User-interface language > 简体中文
Stata使用说明
【如何安装命令】
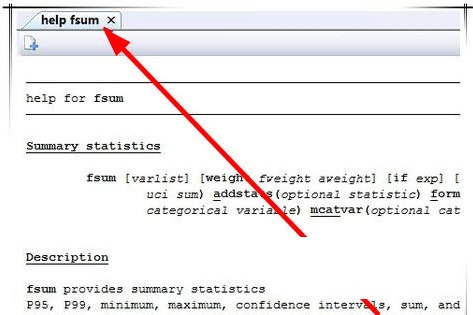
首先,打开Stata官方版,确定自己安装的命令是否已经在stata系统之中,简单的一个测试方法便是在输入框中输入“help XXX”,以“fsum”命令为例,输入“h fsum”。
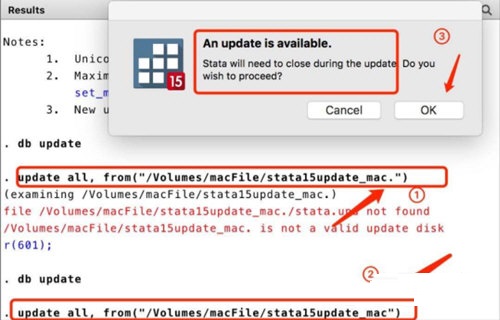
如果没有该命令,则会出现图片的提示。这里也可以选择“是”来软件自动搜索,但是我们提供另外一个下载方式。
我们可以直接在stata命令窗口中输入下载命令:“ssc install fsum”命令,点击就安装到本地了,一般放在C盘的ado文件夹里面。
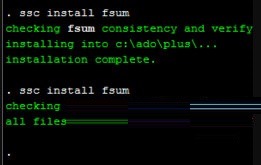
等待下载,当出现以上图样的时候,命令便下载完成了。
最后检验一下新命令是否添加完成,采用上述方法输入“h fsum”命令查询即可。
【如何导入数据】
利用命令导入:
use
1.insheet using filename, [option]
这个命令是专门用来导入像excel之类的以电子表格形式存储的数据。在导入之前,首先要把excel文件转存为STATA可以识别的格式。其中我最常用的就是另存为csv逗号分隔符格式。
然后在STATA中使用insheet读取csv文件,在option中指定为comma告诉STATA你读取的是csv文件。
这种方法有个不足在于如果你的数据中包含中文而且里面含有逗号时无法识别,解决的办法是不要用逗号标示分隔符了,在excel中另存为txt(制表符分隔),这样就不会与逗号相混淆了。然后再在insheet命令中在option里指定是tab,就完事了。
2.infile using filename
这个infile命令分两类,一种是处理固定格式(fixed format)的txt或raw,另一种是处理自由格式(free format),当然你在用这个命令里还需要定义一个dictionary,这个dictionary是用来描述数据的组织方式的,需要自己根据要导入的数据文件自己编写代码,然后嵌套到数据文件txt的前面去,或者是单独地存为一个dct文件,并且告诉STATA你要导入的数据在保存在哪里。
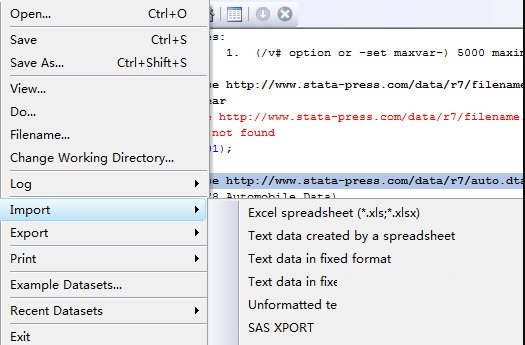
3.xmluse
这个命令首先要把xls文件另存为xml格式,然后用xmluse命令去读取,当然在读取时你也要在option中声明你的xml文件是excel保存的而不是STATA保存的,这样就不会弄错。
如果你的xls文件中如果有汉字的话,STATA读取后对应的变量会出现乱码,这一点用insheet就不会有这个问题。
4.odbc
这个命令是专门读取数据库文件的,并且支持SQL命令,这样如果你的数据比较多的话,可以先用SQL语句进行筛选,然后而导入。当然这个命令也能导向excel文件。
【怎么合并数据】
使用merge命令语法:merge [varlist] using filename [filename...] [,optione];其中[varlist]代表合并进去的新变量,using filename指的是所要与原文件合并的文件路径

首先打开第一个源文件water1.dta,将它按year排序,然后再以覆盖方式保存
再打开第二个源文件water2.dta,将它按year排序
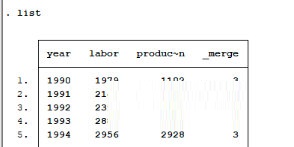
用merge命令进行两个文件的合并
保存合并后的结果,并查看合并后的数据
【怎么用折线把散点连接起来】
右击图表区域
更改图表类型-带平滑线和数据标记的散点图
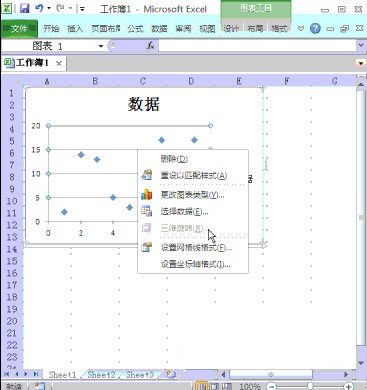
进入后选择相应的模块就好了
查看效果(OK)
或者使用命令twoway (scatter y x) (lfit y x)
“ lfit"表示”linear fit"(线性拟合),形状为直线,如果想在散点图上同时画出二次回归曲线,直接将“ lfit"改为“qfit",(二次拟合),形状为曲线。

【怎么导出回归结果】
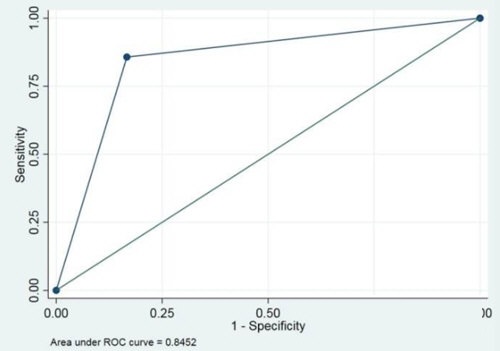
Step1:进行命令分析,如回归分析(命令结果如下)
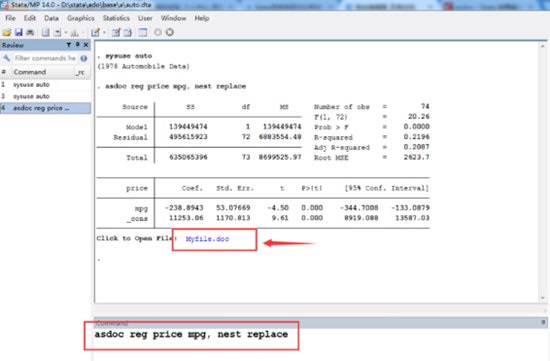
Step2:(输入命令)outreg2 using myfile(结果导出命令)
Step3 :(输入命令)findit outreg2(找outreg2命令)
Step4:点击界面中的链接(fmwww.bc.edu),会出现 clink here to install 按钮,点击进入
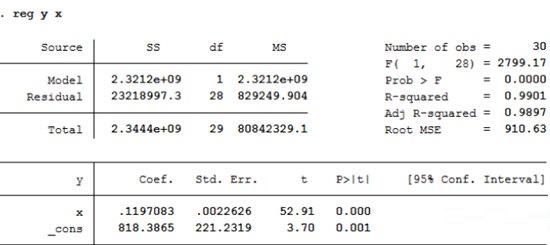
Step5:(再次输入命令)outreg2 using myfile(结果导出命令)就可以导出回归结果了。
常见问题
缺失值处理:
问题描述:数据中的缺失值可能导致分析结果不准确。
解决方案:在进行分析之前,使用STATA的missing()函数检查缺失值,并选择合适的处理方法,如删除缺失值、填补缺失值(使用均值、中位数或众数填补)或基于模型的方法(如多重插补)。
数据类型转换:
问题描述:在进行统计分析时,可能需要将某些数据类型转换为适合分析的类型(如将字符串类型转换为数值类型)。
解决方案:使用STATA的destring、real()等命令进行数据类型转换。在转换前,请确保了解数据的实际含义和转换后的影响。
Stata更新日志
1、修复上个版本的bug
2、优化部分功能
番茄下载站小编推荐:
Stata属免费软件,有需要的就下载吧!本站还有{recommendWords},供您下载!






























